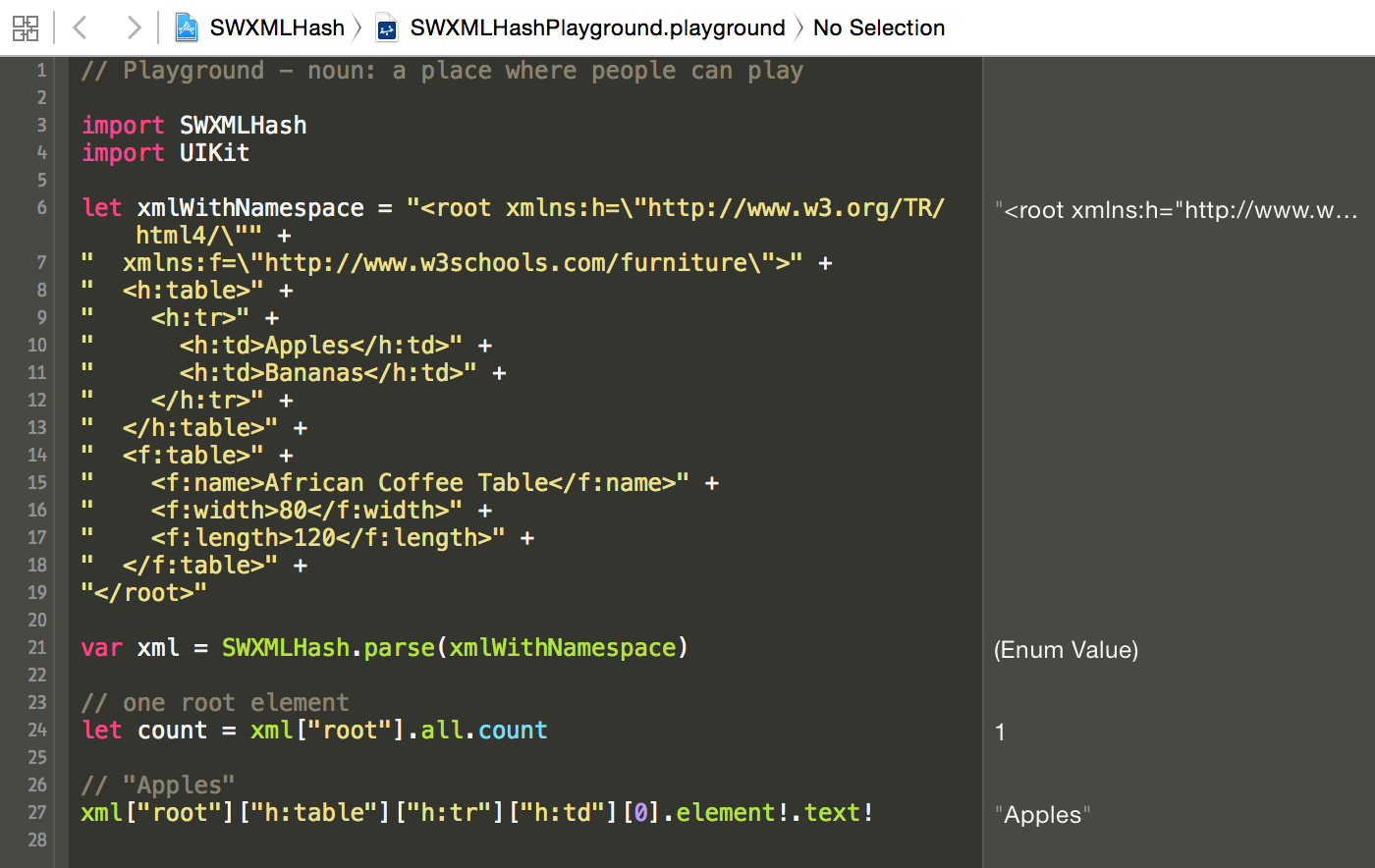
SWXMLHash 是在 Swift 中解析 XML 的相对简单方法。如果您熟悉 NSXMLParser,这个库是其简单封装。从概念上来说,它提供 XML 到数组和字典(即散列)的转换。
API 从 SwiftyJSON 中汲取了很多灵感。
iOS 8.0+/ Mac OS X 10.9+/ tvOS 9.0+/ watchOS 2.0+
Xcode 8.0+
SWXMLHash 可以使用 CocoaPods 、Carthage 、Swift 包管理器 或手动方式安装。
要安装 CocoaPods,请运行
然后创建一个具有以下内容的 Podfile
platform :ios , '10.0'
use_frameworks!
target 'YOUR_TARGET_NAME' do
pod 'SWXMLHash' , '~> 7.0.0'
end 最后,运行以下命令进行安装
要安装 Carthage,请运行(使用 Homebrew)
$ brew update
$ brew install carthage 然后在你的 Cartfile 中添加以下行
github "drmohundro/SWXMLHash" ~> 7.0
Swift 包管理器需要 Swift 版本 4.0 或更高。首先,创建一个 Package.swift 文件。它应如下所示
dependencies: [
.package (url : " https://github.com/drmohundro/SWXMLHash.git" from : " 7.0.0" 然后运行 swift build,这将为您下载并编译 SWXMLHash,以便您开始使用。
要手动安装,您需要克隆SWXMLHash存储库。您可以在单独的目录中执行此操作,或者可以使用git子模块——在这种情况下,建议使用git子模块,这样您的存储库将包含有关您正在使用的SWXMLHash的哪个提交的详细信息。一旦完成,您只需将所有相关的swift文件放入项目中即可。
如果您正在使用工作区,则可以仅包含整个SWXMLHash.xcodeproj。
如果你刚开始使用SWXMLHash,我建议克隆存储库并打开工作区。我在工作区中包括了一个Swift playground,这使得在API和调用上进行实验变得容易。
SWXMLHash允许在解析方法方面进行有限的配置。要设置任何配置选项,您使用如下的configure方法
let xml = XMLHash.config {
config in
// set any config options hereparse (xmlToParse)目前可用的选项包括
shouldProcessLazily
此选项确定是否使用XML的懒加载。如果您的大型XML,则这可以显着提高解析性能。
默认为false
shouldProcessNamespaces
此设置将传递给内部NSXMLParser实例。它将返回不带其命名空间部分的任何XML元素(即,“<h:table>”将返回为“<table>”)
默认为false
caseInsensitive
此设置允许进行不区分大小写的键查找。通常,XML是一种区分大小写的语言,但此选项可以在必要时绕过此限制。
默认为false
encoding
此设置允许在将XML字符串传递给parse时显式指定字符编码。
默认为String.encoding.utf8
userInfo
detectParsingErrors
此设置尝试检测XML解析错误。如果在解析过程中发现任何问题,parse将返回一个XMLIndexer.parsingError。
默认为false(因为向后兼容性,以及许多用户尝试使用此库解析HTML)
下面所有的示例都可以在包含的规范 中找到。
let xml = XMLHash.parse (xmlToParse)如果正在解析一个大型XML文件并且需要最佳性能,可以选择将解析配置为懒加载。懒加载 avoidsloading the entire XML document into memory, 因此在性能方面可能更可取。有关有关懒加载的一个注意事项,请参阅错误处理。
let xml = XMLHash.config {
config in
config.shouldProcessLazily = true
}.parse (xmlToParse)上述方法使用新的config方法,但还有XMLHash的直接lazy方法。
let xml = XMLHash.lazy (xmlToParse)给定
<root >
<header >
<title >Foo</title >
</header >
...
</root > 将返回 "Foo"。
xml[" root" " header" " title" element ? .text 给定
<root >
...
<catalog >
<book ><author >Bob</author ></book >
<book ><author >John</author ></book >
<book ><author >Mark</author ></book >
</catalog >
...
</root > 下面将返回 "John"。
xml[" root" " catalog" " book" 1 ][" author" element ? .text 给定
<root >
...
<catalog >
<book id =" 1" author >Bob</author ></book >
<book id =" 123" author >John</author ></book >
<book id =" 456" author >Mark</author ></book >
</catalog >
...
</root > 以下将返回 "123"。
xml[" root" " catalog" " book" 1 ].element ? .attribute (by : " id" ? .text 或者,您可以查找具有特定属性的事件。以下将返回 "John"。
xml[" root" " catalog" " book" withAttribute (" id" " 123" " author" element ? .text 给定
<root >
...
<catalog >
<book ><genre >Fiction</genre ></book >
<book ><genre >Non-fiction</genre ></book >
<book ><genre >Technical</genre ></book >
</catalog >
...
</root > 使用 all 方法将遍历索引级别的所有节点。以下将返回 "Fiction, Non-fiction, Technical"。
" , " join (xml[" root" " catalog" " book" all .map { elem in
elem[" genre" element ! .text !
})您还可以迭代all方法
for elem in xml[" root" " catalog" " book" all {
print (elem[" genre" element ! .text ! )
}给定
<root >
<catalog >
<book >
<genre >Fiction</genre >
<title >Book</title >
<date >1/1/2015</date >
</book >
</catalog >
</root > 以下将 print "root", "catalog", "book", "genre", "title", 和 "date"(注意children方法)。
func enumerate (indexer for child in indexer.children {
print (child.element ! .name )
enumerate (child)
}
}
enumerate (indexer : xml)给定
<root >
<catalog >
<book id =" bk101" author >Gambardella, Matthew</author >
<title >XML Developer's Guide</title >
<genre >Computer</genre ><price >44.95</price >
<publish_date >2000-10-01</publish_date >
</book >
<book id =" bk102" author >Ralls, Kim</author >
<title >Midnight Rain</title >
<genre >Fantasy</genre >
<price >5.95</price >
<publish_date >2000-12-16</publish_date >
</book >
<book id =" bk103" author >Corets, Eva</author >
<title >Maeve Ascendant</title >
<genre >Fantasy</genre >
<price >5.95</price >
<publish_date >2000-11-17</publish_date >
</book >
</catalog >
</root > 以下将返回 "Midnight Rain"。筛选可以基于XMLElement类的任何部分或索引。
let subIndexer = xml! [" root" " catalog" " book" filterAll { elem, _ in elem.attribute (by : " id" ! .text == " bk102" filterChildren { _ , index in index >= 1 && index <= 3 }
print (subIndexer.children [0 ].element ? .text )使用 Swift 2.0 的新错误处理功能
do {
try xml! .byKey (" root" byKey (" what" byKey (" header" byKey (" foo" catch let error as IndexingError {
// error is an IndexingError instance that you can deal with或者 使用现有的索引功能
switch xml[" root" " what" " header" " foo" case .element (let elem):
// everything is good, code away!case .xmlError (let error):
// error is an IndexingError instance that you can deal with请注意,如上所示的错误处理方式不适用于懒加载的 XML。懒解析实际上在调用 element 或 all 方法时才会发生 - 因此,在请求元素之前,无法知道元素是否已存在。
更频繁的情况下,您可能希望将 XML 树反序列化为自定义类型的数组。这就是 XMLObjectDeserialization 发挥作用的地方。
给定
<root >
<books >
<book isbn =" 0000000001" title >Book A</title >
<price >12.5</price >
<year >2015</year >
<categories >
<category >C1</category >
<category >C2</category >
</categories >
</book >
<book isbn =" 0000000002" title >Book B</title >
<price >10</price >
<year >1988</year >
<categories >
<category >C2</category >
<category >C3</category >
</categories >
</book >
<book isbn =" 0000000003" title >Book C</title >
<price >8.33</price >
<year >1990</year >
<amount >10</amount >
<categories >
<category >C1</category >
<category >C3</category >
</categories >
</book >
</books >
</root > 使用实现了 XMLObjectDeserialization 的 Book 结构体
struct Book : XMLObjectDeserialization {
let title: String
let price: Double
let year: Int
let amount: Int ?
let isbn: Int
let category: [String ]
static func deserialize (_ node : XMLIndexer) throws -> Book {
return try Book (
title : node[" title" value (),
price : node[" price" value (),
year : node[" year" value (),
amount : node[" amount" value (),
isbn : node.value (ofAttribute : " isbn" category : node[" categories" " category" value ()
)
}
}以下将返回 Book 结构体的数组
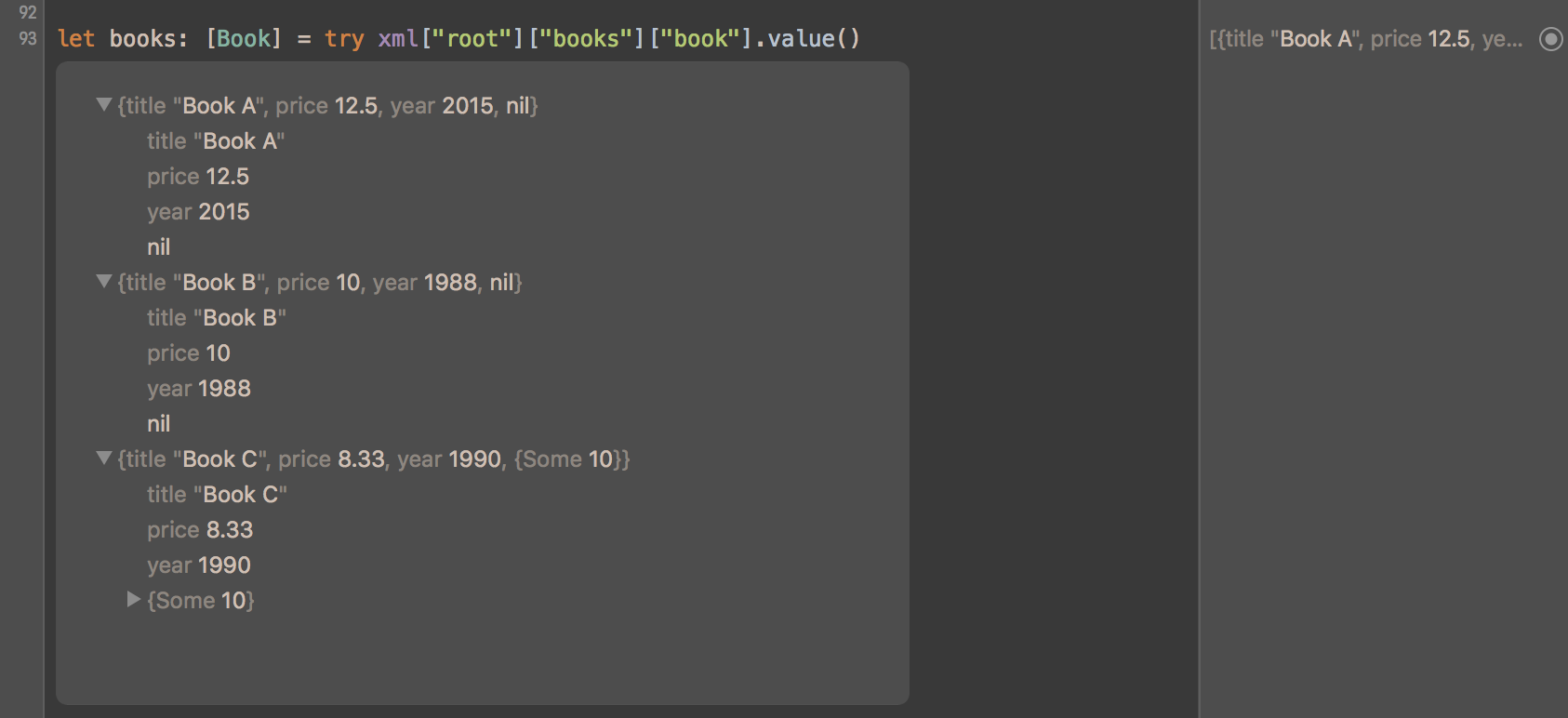
let books: [Book] = try xml[" root" " books" " book" value ()
您可以通过为任何非叶节点(例如上面示例中的 ``)实现 XMLObjectDeserialization 来将任何 XML 转换为您自定义的类型。
对于叶节点(例如上面的 `
`),内建的转换器支持 <code>Int</code>、<code>Double</code>、<code>Float</code>、<code>Bool</code> 和 <code>String</code> 值(均为非可选和可选变体)。可以通过实现 <code>XMLElementDeserializable</code> 添加自定义转换器。</p>
<p dir="auto">对于属性(例如上面的 `isbn=`),内建的转换器支持与上面相同的类型,并且可以通过实现 <code>XMLAttributeDeserializable</code> 添加额外的转换器。</p>
<p dir="auto">类型转换支持错误处理、可选和数组。有关更多示例,请参阅 <code>SWXMLHashTests.swift</code> 或直接在 Swift playground 中玩转类型转换。</p>
<h3 dir="auto"><a id="用户内容自定义值转换" class="anchor" aria-hidden="true" href="#自定义值转换"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>自定义值转换</h3>
<p dir="auto">值反序列化是将特定字符串值反序列化到自定义类型的地方。所以,日期是一个很好的例子 - 你宁愿处理日期类型而不愿意进行字符串解析,对吧?这就是 <code>XMLValueDeserialization</code> 属性的作用。</p>
<p dir="auto">给定</p>
<div class="highlight highlight-text-xml notranslate position-relative overflow-auto" dir="auto" data-snippet-clipboard-copy-content="<root>
<elem>Monday, 23 January 2016 12:01:12 111</elem>
</root>"><pre><<span class="pl-ent">root</span>>
<<span class="pl-ent">elem</span>>Monday, 23 January 2016 12:01:12 111</<span class="pl-ent">elem</span>>
</<span class="pl-ent">root</span>></pre></div>
<p dir="auto">以下为 <code>Date</code> 值反序列化的实现</p>
<div class="highlight highlight-source-swift notranslate position-relative overflow-auto" dir="auto" data-snippet-clipboard-copy-content="extension Date: XMLValueDeserialization {
public static func deserialize(_ element: XMLHash.XMLElement) throws -> Date {
let date = stringToDate(element.text)
guard let validDate = date else {
throw XMLDeserializationError.typeConversionFailed(type: "Date", element: element)
}
return validDate
}
public static func deserialize(_ attribute: XMLAttribute) throws -> Date {
let date = stringToDate(attribute.text)
guard let validDate = date else {
throw XMLDeserializationError.attributeDeserializationFailed(type: "Date", attribute: attribute)
}
return validDate
}
public func validate() throws {
// empty validate... only necessary for custom validation logic after parsing
}
private static func stringToDate(_ dateAsString: String) -> Date? {
let dateFormatter = DateFormatter()
dateFormatter.dateFormat = "EEEE, dd MMMM yyyy HH:mm:ss SSS"
return dateFormatter.date(from: dateAsString)
}
}"><pre><span class="pl-k">extension</span> <span class="pl-en">Date</span>: <span class="pl-e">XMLValueDeserialization </span>{
<span class="pl-k">public</span> <span class="pl-k">static</span> <span class="pl-k">func</span> <span class="pl-en">deserialize</span>(<span class="pl-en">_</span> <span class="pl-smi">element</span>: XMLHash.XMLElement) <span class="pl-k">throws</span> <span class="pl-k">-></span> Date {
<span class="pl-k">let</span> date <span class="pl-k">=</span> <span class="pl-c1">stringToDate</span>(element.<span class="pl-c1">text</span>)
<span class="pl-k">guard</span> <span class="pl-k">let</span> validDate <span class="pl-k">=</span> date <span class="pl-k">else</span> {
<span class="pl-k">throw</span> XMLDeserializationError.<span class="pl-c1">typeConversionFailed</span>(<span class="pl-c1">type</span>: <span class="pl-s"><span class="pl-pds">"</span>Date<span class="pl-pds">"</span></span>, <span class="pl-c1">element</span>: element)
}
<span class="pl-k">return</span> validDate
}
<span class="pl-k">public</span> <span class="pl-k">static</span> <span class="pl-k">func</span> <span class="pl-en">deserialize</span>(<span class="pl-en">_</span> <span class="pl-smi">attribute</span>: XMLAttribute) <span class="pl-k">throws</span> <span class="pl-k">-></span> Date {
<span class="pl-k">let</span> date <span class="pl-k">=</span> <span class="pl-c1">stringToDate</span>(attribute.<span class="pl-c1">text</span>)
<span class="pl-k">guard</span> <span class="pl-k">let</span> validDate <span class="pl-k">=</span> date <span class="pl-k">else</span> {
<span class="pl-k">throw</span> XMLDeserializationError.<span class="pl-c1">attributeDeserializationFailed</span>(<span class="pl-c1">type</span>: <span class="pl-s"><span class="pl-pds">"</span>Date<span class="pl-pds">"</span></span>, <span class="pl-c1">attribute</span>: attribute)
}
<span class="pl-k">return</span> validDate
}
<span class="pl-k">public</span> <span class="pl-k">func</span> <span class="pl-en">validate</span>() <span class="pl-k">throws</span> {
<span class="pl-c"><span class="pl-c">//</span> empty validate... only necessary for custom validation logic after parsing</span>
<span class="pl-c"></span> }
<span class="pl-k">private</span> <span class="pl-k">static</span> <span class="pl-k">func</span> <span class="pl-en">stringToDate</span>(<span class="pl-en">_</span> <span class="pl-smi">dateAsString</span>: <span class="pl-c1">String</span>) <span class="pl-k">-></span> Date<span class="pl-k">?</span> {
<span class="pl-k">let</span> dateFormatter <span class="pl-k">=</span> <span class="pl-c1">DateFormatter</span>()
dateFormatter.<span class="pl-smi">dateFormat</span> <span class="pl-k">=</span> <span class="pl-s"><span class="pl-pds">"</span>EEEE, dd MMMM yyyy HH:mm:ss SSS<span class="pl-pds">"</span></span>
<span class="pl-k">return</span> dateFormatter.<span class="pl-c1">date</span>(<span class="pl-c1">from</span>: dateAsString)
}
}</pre></div>
<p dir="auto">以下将返回日期值</p>
<div class="highlight highlight-source-swift notranslate position-relative overflow-auto" dir="auto" data-snippet-clipboard-copy-content="let dt: Date = try xml["root"]["elem"].value()"><pre><span class="pl-k">let</span> dt: Date <span class="pl-k">=</span> <span class="pl-k">try</span> xml[<span class="pl-s"><span class="pl-pds">"</span>root<span class="pl-pds">"</span></span>][<span class="pl-s"><span class="pl-pds">"</span>elem<span class="pl-pds">"</span></span>].<span class="pl-c1">value</span>()</pre></div>
<h2 dir="auto"><a id="user-content-faq" class="anchor" aria-hidden="true" href="#faq"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>常见问题解答</h2>
<h3 dir="auto"><a id="user-content-does-swxmlhash-handle-urls-for-me" class="anchor" aria-hidden="true" href="#does-swxmlhash-handle-urls-for-me"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>SWXMLHash是否为我处理URL?</h3>
<p dir="auto">不是的 - SWXMLHash只处理XML的解析。如果你有一个包含XML内容的URL,我建议使用例如<a href="https://github.com/Alamofire/Alamofire">AlamoFire</a>这样的库将内容下载为一个字符串,然后对其进行解析。</p>
<h3 dir="auto"><a id="user-content-does-swxmlhash-support-writing-xml-content" class="anchor" aria-hidden="true" href="#does-swxmlhash-support-writing-xml-content"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>SWXMLHash支持写入XML内容吗?</h3>
<p dir="auto">目前不支持 - SWXMLHash只支持通过索引、反序列化等方式解析XML。</p>
<h3 dir="auto"><a id="user-content-im-getting-an-ambiguous-reference-to-member-subscript-when-i-call-value" class="anchor" aria-hidden="true" href="#im-getting-an-ambiguous-reference-to-member-subscript-when-i-call-value"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>当我调用<code>.value()</code>时,我遇到了"对于成员'subscript'的引用不明确"的错误。</h3>
<p dir="auto"><code>.value()</code>用于反序列化 - 你必须有一个实现了<code>XMLObjectDeserialization</code>(如果是单个元素而非元素组,则为<code>XMLElementDeserializable</code>)并能够处理对表达式左侧的反序列化的东西。</p>
<p dir="auto">例如,给定以下内容</p>
<div class="highlight highlight-source-swift notranslate position-relative overflow-auto" dir="auto" data-snippet-clipboard-copy-content="let dateValue: Date = try! xml["root"]["date"].value()"><pre><span class="pl-k">let</span> dateValue: Date <span class="pl-k">=</span> <span class="pl-k">try</span><span class="pl-k">!</span> xml[<span class="pl-s"><span class="pl-pds">"</span>root<span class="pl-pds">"</span></span>][<span class="pl-s"><span class="pl-pds">"</span>date<span class="pl-pds">"</span></span>].<span class="pl-c1">value</span>()</pre></div>
<p dir="auto">你会得到错误,因为没有内置的用于 <code>Date</code> 的反序列化程序。请参阅上面关于添加您自己的序列化支持的文档。在这种情况下,你需要为 <code>Date</code> 创建自己的 <code>XMLElementDeserializable</code> 实现。请查看如何添加自己的 <code>Date</code> 反序列化支持的示例。</p>
<h3 dir="auto"><a id="user-content-im-getting-an-exc_bad_access-sigsegv-when-i-call-parse" class="anchor" aria-hidden="true" href="#im-getting-an-exc_bad_access-sigsegv-when-i-call-parse"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>我在调用 <code>parse()</code> 时遇到了 <code>EXC_BAD_ACCESS (SIGSEGV)</code></h3>
<p dir="auto">你的 XML 内容可能含有所谓的 "字节顺序标记" 或 BOM。SWXMLHash 使用 <code>NSXMLParser</code> 进行解析逻辑,并且存在处理 BOM 字符的问题。有关详细信息,请参阅<a href="https://github.com/drmohundro/SWXMLHash/issues/65" data-hovercard-type="discussion" data-hovercard-url="/drmohundro/SWXMLHash/discussions/65/hovercard">问题 #65</a>。遇到此问题的其他人已经在解析之前删除了内容中的 BOM。</p>
<h3 dir="auto"><a id="user-content-how-do-i-handle-deserialization-with-a-class-versus-a-struct-such-as-with-nsdate" class="anchor" aria-hidden="true" href="#how-do-i-handle-deserialization-with-a-class-versus-a-struct-such-as-with-nsdate"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>如何处理类与结构体(如使用 <code>NSDate</code>)的反序列化?</h3>
<p dir="auto">在类上使用扩展而不是结构体会导致一些不太常见的问题,这些可能会给你带来一些麻烦。例如,请参阅 <a href="http://stackoverflow.com/questions/38174669/how-to-deserialize-nsdate-with-swxmlhash" rel="nofollow">StackOverflow 上的这个问题</a>,其中有人尝试为类 <code>NSDate</code>(它不是结构体)编写自己的 <code>XMLElementDeserializable</code>。 <code>XMLElementDeserializable</code> 协议期望一个返回 <code>Self</code> 的方法 - 这部分可能有点复杂。</p>
<p dir="auto">以下是一些代码片段,可以完成此操作,并请注意,重点在于 <code>private static func value<T>() -> T</code> 这一行 - 这才是关键。</p>
<div class="highlight highlight-source-swift notranslate position-relative overflow-auto" dir="auto" data-snippet-clipboard-copy-content="extension NSDate: XMLElementDeserializable {
public static func deserialize(_ element: XMLElement) throws -> Self {
guard let dateAsString = element.text else {
throw XMLDeserializationError.nodeHasNoValue
}
let dateFormatter = NSDateFormatter()
dateFormatter.dateFormat = "EEE, dd MMM yyyy HH:mm:ss zzz"
let date = dateFormatter.dateFromString(dateAsString)
guard let validDate = date else {
throw XMLDeserializationError.typeConversionFailed(type: "Date", element: element)
}
// NOTE THIS
return value(validDate)
}
// AND THIS
private static func value<T>(date: NSDate) -> T {
return date as! T
}
}"><pre><span class="pl-k">extension</span> <span class="pl-en">NSDate</span>: <span class="pl-e">XMLElementDeserializable </span>{
<span class="pl-k">public</span> <span class="pl-k">static</span> <span class="pl-k">func</span> <span class="pl-en">deserialize</span>(<span class="pl-en">_</span> <span class="pl-smi">element</span>: XMLElement) <span class="pl-k">throws</span> <span class="pl-k">-></span> <span class="pl-c1">Self</span> {
<span class="pl-k">guard</span> <span class="pl-k">let</span> dateAsString <span class="pl-k">=</span> element.<span class="pl-c1">text</span> <span class="pl-k">else</span> {
<span class="pl-k">throw</span> XMLDeserializationError.<span class="pl-smi">nodeHasNoValue</span>
}
<span class="pl-k">let</span> dateFormatter <span class="pl-k">=</span> <span class="pl-c1">NSDateFormatter</span>()
dateFormatter.<span class="pl-smi">dateFormat</span> <span class="pl-k">=</span> <span class="pl-s"><span class="pl-pds">"</span>EEE, dd MMM yyyy HH:mm:ss zzz<span class="pl-pds">"</span></span>
<span class="pl-k">let</span> date <span class="pl-k">=</span> dateFormatter.<span class="pl-c1">dateFromString</span>(dateAsString)
<span class="pl-k">guard</span> <span class="pl-k">let</span> validDate <span class="pl-k">=</span> date <span class="pl-k">else</span> {
<span class="pl-k">throw</span> XMLDeserializationError.<span class="pl-c1">typeConversionFailed</span>(<span class="pl-c1">type</span>: <span class="pl-s"><span class="pl-pds">"</span>Date<span class="pl-pds">"</span></span>, <span class="pl-c1">element</span>: element)
}
<span class="pl-c"><span class="pl-c">//</span> NOTE THIS</span>
<span class="pl-c"></span> <span class="pl-k">return</span> <span class="pl-c1">value</span>(validDate)
}
<span class="pl-c"><span class="pl-c">//</span> AND THIS</span>
<span class="pl-c"></span> <span class="pl-k">private</span> <span class="pl-k">static</span> <span class="pl-k">func</span> <span class="pl-en">value</span><<span class="pl-c1">T</span>>(<span class="pl-smi"><span class="pl-en">date</span></span>: NSDate) <span class="pl-k">-></span> T {
<span class="pl-k">return</span> date <span class="pl-k">as!</span> T
}
}</pre></div>
<h3 dir="auto"><a id="user-content-how-do-i-handle-deserialization-with-an-enum" class="anchor" aria-hidden="true" href="#how-do-i-handle-deserialization-with-an-enum"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>如何处理枚举的反序列化?</h3>
<p dir="auto">查看来自 @woolie 的这个出色的建议/示例,他(她)在 <a class="issue-link js-issue-link" data-error-text="加载数据失败" data-id="3206391" data-permission-text="标题是私有的" data-url="https://github.com/drmohundro/SWXMLHash/discussions/245" data-hovercard-type="讨论" data-hovercard-url="/drmohundro/SWXMLHash/discussions/245/hovercard" href="https://github.com/drmohundro/SWXMLHash/discussions/245">#245</a> 的 GitHub 讨论页。</p>
<h3 dir="auto"><a id="user-content-im-seeing-an-xmlelement-is-ambiguous-error" class="anchor" aria-hidden="true" href="#im-seeing-an-xmlelement-is-ambiguous-error"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>我遇到了一个 "''XMLElement' 是模糊的" 错误</h3>
<p dir="auto">这与 <a class="issue-link js-issue-link" data-error-text="加载数据失败" data-id="1167265133" data-permission-text="标题是私有的" data-url="https://github.com/drmohundro/SWXMLHash/issues/256" data-hovercard-type="问题" data-hovercard-url="/drmohundro/SWXMLHash/issues/256/hovercard" href="https://github.com/drmohundro/SWXMLHash/issues/256">#256</a> 有关 - <code>XMLElement</code> 实际上已经被重命名多次以避免冲突,但最简单的方法是使用 <code>XMLHash.XMLElement</code> 进行范围限定。</p>
<h3 dir="auto"><a id="user-content-will-swxmlhash-work-in-a-web-context-eg-vapor" class="anchor" aria-hidden="true" href="#will-swxmlhash-work-in-a-web-context-eg-vapor"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>SWXMLHash 在 Web 上下文(例如 Vapor)中工作吗?</h3>
<p dir="auto">请参阅 <a class="issue-link js-issue-link" data-error-text="加载数据失败" data-id="4277252" data-permission-text="标题是私有的" data-url="https://github.com/drmohundro/SWXMLHash/discussions/264" data-hovercard-type="讨论" data-hovercard-url="/drmohundro/SWXMLHash/discussions/264/hovercard" href="https://github.com/drmohundro/SWXMLHash/discussions/264">#264</a> 以了解讨论内容。所需的唯一更改是添加以下导入逻辑</p>
<div class="highlight highlight-source-swift notranslate position-relative overflow-auto" dir="auto" data-snippet-clipboard-copy-content="#if canImport(FoundationNetworking)
import FoundationNetworking
#endif"><pre>#<span class="pl-k">if</span> <span class="pl-k">canImport</span>(<span class="pl-en">FoundationNetworking</span>)
<span class="pl-k">import</span> <span class="pl-en">FoundationNetworking</span>
#<span class="pl-k">endif</span></pre></div>
<h3 dir="auto"><a id="user-content-have-a-different-question" class="anchor" aria-hidden="true" href="#have-a-different-question"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>有不同的问题吗?</h3>
<p dir="auto">请随时给我发邮件,在 <a href="http://stackoverflow.com/questions/tagged/swxmlhash" rel="nofollow">StackOverflow 上提问</a>,或者如果您认为发现了错误,可以打开一个问题。我将很乐意尝试帮助!</p>
<p dir="auto">另一种选择是在 <a href="https://github.com/drmohundro/SWXMLHash/discussions">讨论</a> 中提问。</p>
<h2 dir="auto"><a id="user-content-changelog" class="anchor" aria-hidden="true" href="#changelog"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>更新日志</h2>
<p dir="auto">查看<a href="CHANGELOG.md">更新日志</a>来了解所有变更及其对应版本。</p>
<h2 dir="auto"><a id="user-content-contributing" class="anchor" aria-hidden="true" href="#contributing"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>贡献</h2>
<p dir="auto">查看<a href="CONTRIBUTING.md">贡献指南</a>了解如何向SWXMLHash做出贡献。</p>
<h2 dir="auto"><a id="user-content-license" class="anchor" aria-hidden="true" href="#license"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg></a>许可</h2>
<p dir="auto">SWXMLHash遵循MIT许可协议发布。详情请见<a href="LICENSE">许可</a>。</p>
</article></div></div><div class="tab-pane" id="changelog_content"></div></div></div><div class="clearfix"></div></div></article></section></div><script>$copy_to_clipboard = $('ol.results img.copy')
var clip = new ZeroClipboard(
$copy_to_clipboard, {
moviePath: "/flashes/ZeroClipboard.swf",
forceHandCursor: true
}
);
clip.on( 'noflash', function ( client, args ) {
// provide a recursive wait method
// that checks for the hover on the popover/clipboard
// before hiding so you can select text
function closePopoverForNode(node){
setTimeout(function() {
if (!$(node).is(':hover') && !$(".popover:hover").length) {
$(node).popover("hide")
} else {
closePopoverForNode(node)
}
}, 500);
}
// With no flash you should be able to select the text
// in the popover
$copy_to_clipboard.popover({
trigger: "manual",
container: "body"
}).on("click", function(e) {
e.preventDefault();
}).on("mouseenter", function() {
$(this).popover("show");
$(".popover input").select()
}).on("mouseleave", function() {
closePopoverForNode(this)
});
});
// When Flash works, jusst do a normal popover
clip.on("load", function(client) {
client.on( "complete", function(client, args) {
$("h4.has-flash").text("Saved to clipboard");
$(".popover").addClass("saved")
});
clip.on( 'mouseover', function ( client, args ) {
$(this).popover('show')
});
clip.on( 'mouseout', function ( client, args ) {
$(this).popover('hide')
});
});
// When the page loads up check for a #changelog and load the changelog instead of the README if possible
$(document).ready(function() {
if ($("#asset_switcher").length == 0) { return }
if (location.hash == "#changelog") {
$("#changelog_tab").click()
}
// Make it easy to get a changelog URL for C+Ping
$('#asset_switcher a').on('shown.bs.tab', function (e) {
var is_changelog = $(e.target).data("target") == "#changelog_content"
var new_hash = (is_changelog) ? "#changelog" : ""
var current_url = window.location.toString().split('#')[0]
history.replaceState(null, null, current_url + new_hash)
})
})</script><div class="clearfix"></div><footer class="page-footer"><section class="container"><div class="row"><article class="col-md-8 col-lg-8 col-sm-12 col-md-offset-2 col-lg-offset-2 col-xs-12"><h4>CocoaPods项目由以下团队开发:</h4><p class="contributors"> <a href="https://twitter.com/dnkoutso">Dimitris Koutsogiorgas</a>,<a href="https://dani.builds.terrible.systems/">Danielle Lancashire</a>,<a href="https://github.com/amorde">Eric Amorde</a>,<a href="https://orta.io">Orta Therox</a>,<a href="https://github.com/paulb777">Paul Beusterien</a>,<a href="https://segiddins.me">Samuel Giddins</a>,以及<a href="https://cocoapods.org.cn/about#team">CocoaPods开发团队</a>,同时还得到众多其他人的贡献。</p><h4>由以下企业赞助:</h4><p class="sponsors"><a href="http://artsy.net">Artsy</a>,<a href="http://www.usebutton.com">Button</a>,<a href="http://www.capitalone.io">Capital One</a>,<a href="https://circleci.com">CircleCI</a>,<a href="http://discontinuity.eu">Discontinuity</a>,<a href="http://www.emergetools.com">Emerge Tools</a>,<a href="http://www.fngtps.com">Fingertips</a>,<a href="https://developers.google.com">Google</a>,<a href="https://www.heroku.com">Heroku</a>,<a href="https://www.jsdelivr.com">jsDelivr</a>,<a href="https://realm.io">Realm</a>,<a href="https://pspdfkit.com/">PSPDFKit</a>,<a href="http://www.rubymotion.com">RubyMotion</a>,<a href="https://www.sauspiel.de">Sauspiel</a>,<a href="https://www.slack.com">Slack</a>,<a href="https://www.soundcloud.com">SoundCloud</a>,<a href="https://www.stripe.com">Stripe</a>,<a href="https://www.squareup.com">Square</a>以及<a href="http://www.technologyastronauts.ch">Technology Astronauts</a>。</p></article></div></section></footer><footer class="footer-links"><section class="container"><div class="row"><article class="col-md-8 col-lg-8 col-sm-12 col-md-offset-2 col-lg-offset-2 col-xs-12"><a class="cocoapods-small-logo" href="https://cocoapods.org.cn"></a><ul><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://guides.cocoapods.org.cn/using/troubleshooting.html">支持</a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://github.com/CocoaPods/CocoaPods">GitHub 仓库</a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://status.cocoapods.org">Web属性状态</a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://twitter.com/CocoaPods">@CocoaPods</a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="http://groups.google.com/group/cocoapods">邮件列表</a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://cocoapods.org.cn/about"><span class="visible-lg-span">CocoaPods</span> 开发团队</a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://guides.cocoapods.org.cn/syntax/podfile.html">Podfile 文档<span class="hidden-lg-span">s</span><span class="visible-lg-span">uation</span></a></li><li class="col-md-3 col-sm-3 col-xs-6"><a href="https://cocoapods.org.cn/legal">法律/行为准则</a></li></ul></article></div></section></footer></body></html>